Every major cloud has autoscaling. It's table stakes. But "autoscaling" usually means: observe a metric, cross a threshold, add capacity. That works — until your traffic spikes faster than your VMs boot, or you've padded your fleet so aggressively that you're paying for air. ML can do better. Here's how.
A quick note before we dive in. My PhD thesis was on Auto-Scaling Techniques for Cloud Systems Processing Requests with Service Level Agreements — so this topic is basically where I lived for a few years. I've been meaning to write publicly about cloud scaling and ML for a while, and this is post #1 of what I'm planning as a running series. The goal: document where things actually stood as of early 2024, before things move on again. No hype, just what the research and tooling actually showed up to this point.

The Problem With "Reactive-Only" Scaling
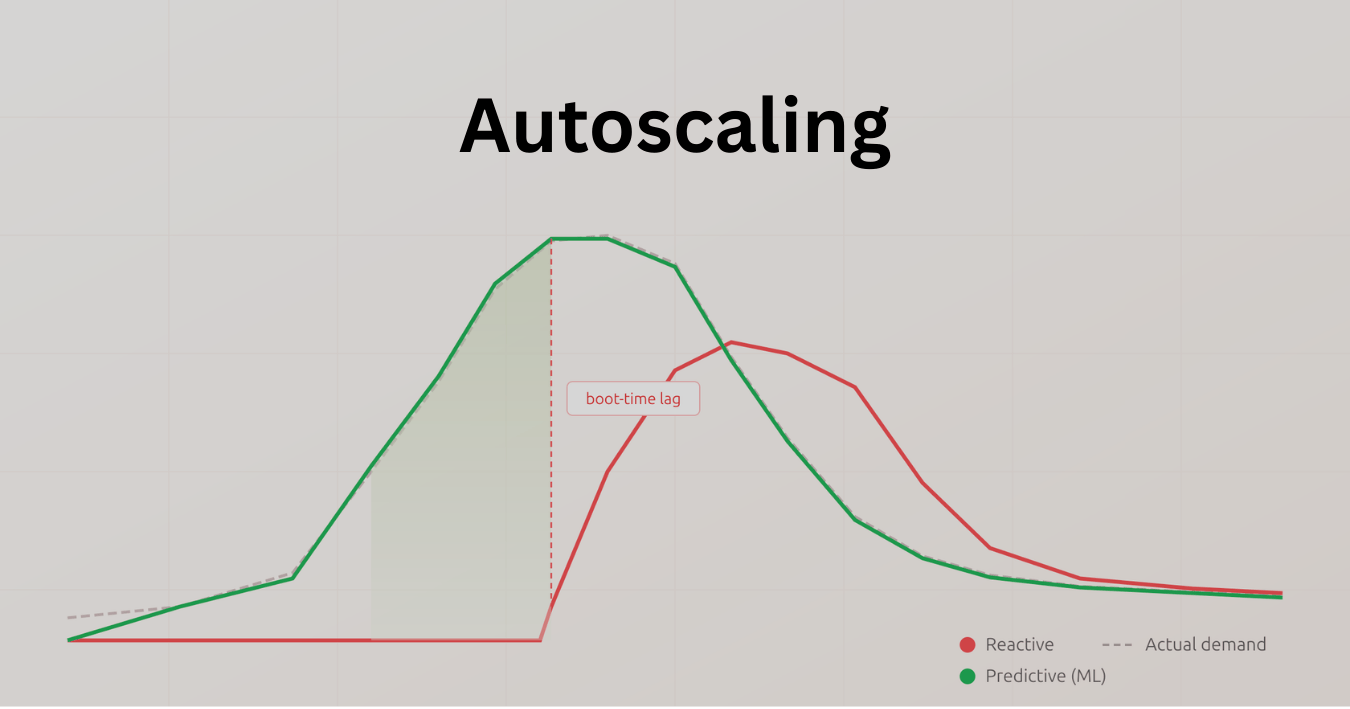
Autoscaling is everywhere. AWS, GCP, Azure — they all do it. But the default mode is fundamentally reactive: watch a metric (usually CPU), cross a threshold, trigger an action. Which is fine for slow, predictable load. The trouble is the real world.
When traffic spikes faster than your VMs boot — and for a lot of workloads, boot times are measured in minutes, not seconds — you've already dropped requests. And the usual workaround is to provision extra capacity "just in case," which means you're paying for headroom you mostly don't use. Neither outcome is great.
ML changes the loop in two pretty distinct ways: forecasting (predicting near-future demand from historical patterns) and policy learning (using reinforcement learning to decide how much to scale and when, optimizing for cost and SLOs simultaneously). These aren't mutually exclusive — hybrid approaches are often more practical anyway.
What "Resource Allocation" Actually Covers
Worth being precise here, because "resource allocation" gets used loosely. I'm talking about three main levers:
Horizontal scaling — changing the number of replicas, VMs, or containers. This is what Kubernetes HPA does, what cloud autoscaler groups do. Most of the predictive ML work lives here.
Vertical scaling — changing CPU/memory limits per instance. Kubernetes VPA handles this. It's less well-covered in the ML literature but matters a lot for right-sizing: a workload that's CPU-bound and one that's I/O-bound have very different optimal allocations even at the same replica count.
Placement and scheduling — which nodes, VM types, or regions to land workloads on. This is where cost optimization gets interesting — spot instances, committed use discounts, region pricing differences.
And cutting across all of these: time-to-ready. Predictive scaling only matters if you predict early enough. If your instances take 4 minutes to boot and your forecast window is 1 minute, you've got a problem. Warm pools and image optimization become critical enablers.
The ML Toolbox
Different problems call for different approaches. Here's roughly how I'd categorize them:
Approach 01: Time-Series Forecasting
ARIMA, Prophet, LSTMs, Transformers. Best when load has clear seasonality — daily, weekly cycles. You forecast future QPS or CPU, then translate that to "desired replicas" with a headroom buffer. This is what cloud-native predictive autoscaling modes operationalize.
Approach 02: Supervised Right-Sizing
Classify workloads by "shape" — CPU-bound, memory-bound, I/O-bound — then recommend resource requests/limits or VM flavors per class. Google's open Borg/ClusterData traces are the canonical training data here. Practical and underrated.
Approach 03: Reinforcement Learning
Learn a policy mapping cluster state → scaling action, with a reward that blends SLO adherence, cost, and stability. Deep RL has shown real promise in research and some industry deployments, though the operational complexity is non-trivial.
Approach 04: Hybrid Strategies
Forecast for baseline capacity, use RL or rules for burst handling. Couple forecasting with queueing models for safer headroom estimates. In practice, hybrids outperform pure approaches because different parts of the problem have different uncertainty profiles.

What the Major Platforms Actually Support
By early 2024, all three major clouds have shipped some form of predictive autoscaling — not just ML research projects but production features. They vary a lot in how opaque the models are.
Kubernetes HPA v2 — external metrics adapter
AWS EC2 Predictive Scaling — GA since 2021
Google Cloud MIG Predictive — cyclical workloads
Azure VMSS Predictive Autoscale — GA, CPU-based ML
The Kubernetes story is interesting because it's more open-ended: HPA v2 lets you plug in external or custom metrics, so you can have your own ML service publish a "desired replicas" signal and HPA just acts on it. It's more DIY, but you keep control of the model. AWS Predictive Scaling analyzes your own historical patterns and pre-warms capacity — especially useful when instance initialization time is non-trivial (think: 3–5 minute AMI boot). Azure's version does something similar but is currently limited to CPU metrics, and Google's MIG predictive mode is most useful for cyclical, daily/weekly patterns.
The Data You Actually Need
None of this works without the right data. The minimum viable inputs for a forecasting model are roughly: 7–14 days of historical load (request rate, CPU, memory, queue depth), your SLO budgets per service or job class, and some understanding of boot times and warm pool behavior so your predictions lead by the right margin.
Feature engineering matters more than model choice here, in my experience. Hour-of-week, holiday flags, moving averages, volatility measures, traffic source mix — these tend to matter more than whether you use an LSTM or a Transformer. And if you're bootstrapping before you have enough production data, Google's open Borg/ClusterData traces are a solid starting point for validating models before going live.
What You're Optimizing For (It's Not One Thing)
Resource allocation is a multi-objective problem. There's no single 'best' policy — there's a Pareto frontier between cost, SLO adherence, and stability.
This is worth sitting with. The reward function for RL (or the loss for a forecasting-plus-rules setup) needs to balance: SLO penalty (heavy weight — latency above threshold is bad), cost penalty (proportional to provisioned capacity over time), and stability (penalize rapid scale churn and cold starts). Getting these weights right for your workload is more art than science.

A Pragmatic Rollout (Don't Start With RL)
The temptation is to go straight to RL because it's exciting. Resist this. Here's how I'd actually roll this out:
Map your init times first. Measure VM or pod time-to-ready across your fleet. Predictive scaling only helps if your forecast window is longer than your boot window. If boot takes 4 minutes, you need to predict 5–6 minutes out minimum.
Start with a demand forecast. Build or use a simple time-series model. Publish a "desired replicas" signal and wire it to HPA as an external metric. Keep a headroom buffer tied explicitly to SLO. This alone beats reactive rules for cyclical workloads.
Close the feedback loop. Compare forecast vs. observed at each interval. Auto-tune your headroom. Add safeguards — max scale-in per window, cool-down periods. This is where most of the reliability gains come from.
Pilot RL on something non-critical. Define reward, train off-policy from logs, run in shadow mode before you canary any real actions. RL for autoscaling is promising, but the iteration cycles for reward shaping are slow and the failure modes can be subtle.
Codify your SLOs as alerts. Alert on error budget burn rate, not just CPU. If your observability stack is still threshold-based on utilization metrics, you're flying blind on whether ML-driven scaling is actually hitting the target.
Common Pitfalls (and How They Actually Bite You)
Noisy or stale signals. If your metrics pipeline has gaps, stale scrape intervals, or missing data during rollouts, your model trains on garbage. Validate freshness and reconcile scraping cadence with your model's expectation window before anything else.
Concept drift after releases. A new service version with a different memory profile or CPU footprint will silently break a model trained on the old behavior. Schedule periodic re-training and add drift detection — even a simple statistical test on recent vs. historical distributions.
Cold starts dominate the tail. If init time is your actual bottleneck, no ML model fixes that directly. Warm pools, image layer caching, and pre-warming during low-traffic windows are still the right tools. Use predictive scaling to trigger the warm-up earlier, not to replace it.
Flapping. RL policies (and some aggressive forecasting setups) can cause rapid oscillation of scale events, which has its own latency cost. Apply stabilization windows, cap changes per time window, and weight the stability term in your reward/loss carefully.
Where This Is Going
The honest answer as of early 2024 is: the theory is ahead of the tooling. Deep RL for autoscaling has strong research results, but production deployments are still relatively rare and usually hybrid. The cloud-native predictive modes are much more approachable for most teams — they're opinionated but they work, and they're where the baseline for "good enough" now sits.
The interesting space is in tighter ML-control plane integration — where the model and the autoscaler have a real feedback loop, not just a one-way recommendation. That's starting to show up in research (Kubernetes schedulers with learned policies, multi-cluster RL) but isn't mainstream yet. More on that in future posts.
This is post #1 in an ongoing series tracing the state of cloud scaling and ML as of March 2024. My thesis — Auto-Scaling Techniques for Cloud Systems Processing Requests with SLAs — is the foundation this series builds from.

Loading comments...